Claude Code 省 Token 指南:慎用 1M 上下文,不开新会话或者总是开新会话都不对
宝玉的分享4754 字 (约 16 分钟)
92
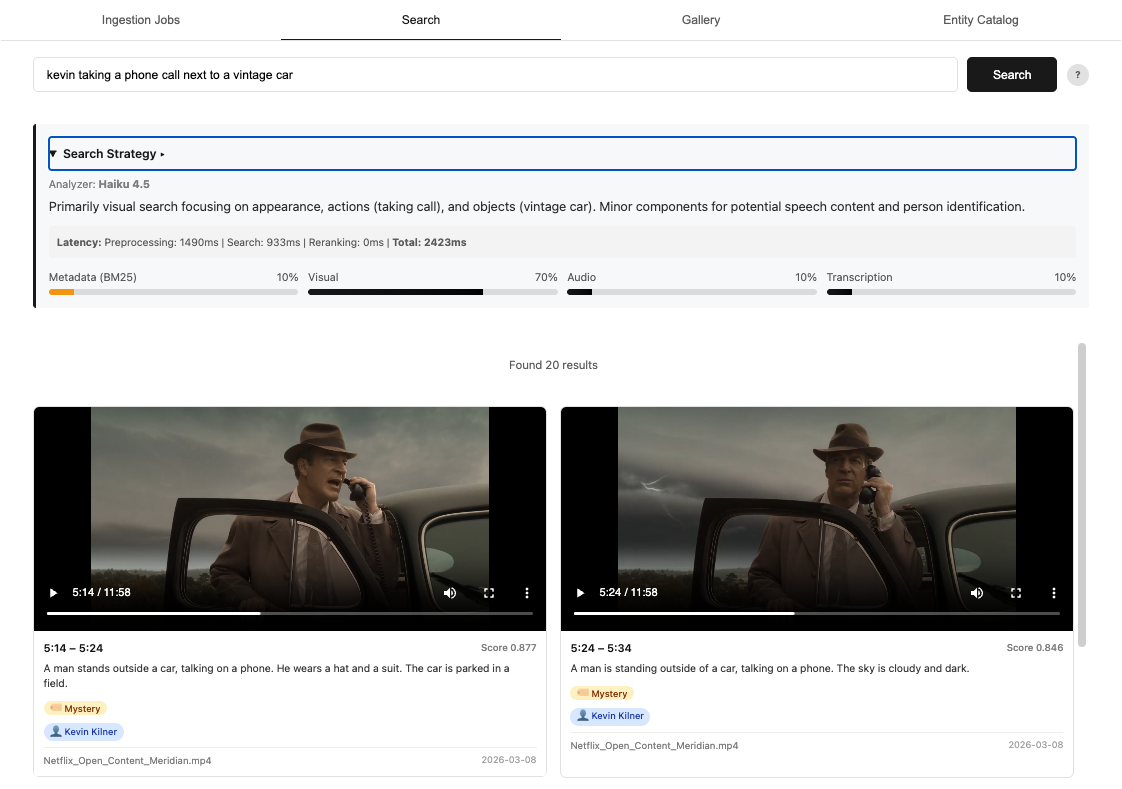
频繁开启新会话会导致提示缓存失效并触发全价重建,保持活跃会话反而更节省Token。 任务未切换且缓存未过期时应继续当前会话,任务变更或闲置超1小时再果断开新会话。 日常开发慎用1M上下文窗口,建议配置自动压缩阈值至20万Token以控制成本并维持性能。
入选理由:频繁开启新会话会导致提示缓存失效并触发全价重建,保持活跃会话反而更节省Token。
AI 内容情报与创作工作台
从技术博客、播客、视频和推文中筛出高质量内容,保存成项目素材,生成研究报告、深读笔记、社媒帖和短视频方案。
从公共质量池中挑出的高质量内容
频繁开启新会话会导致提示缓存失效并触发全价重建,保持活跃会话反而更节省Token。 任务未切换且缓存未过期时应继续当前会话,任务变更或闲置超1小时再果断开新会话。 日常开发慎用1M上下文窗口,建议配置自动压缩阈值至20万Token以控制成本并维持性能。
入选理由:频繁开启新会话会导致提示缓存失效并触发全价重建,保持活跃会话反而更节省Token。
微软研究院联合高校提出ADeLe评估框架,通过18项核心能力维度对大模型与任务进行双向量化评分。该方法能构建模型能力画像,以约88%的准确率预测未知任务表现,并精准定位模型失败原因,有效弥补传统基准测试缺乏解释性与预测力的缺陷。
入选理由:ADeLe将模型与任务映射至18项核心能力维度(0-5分),实现需求与能力的结构化对齐。
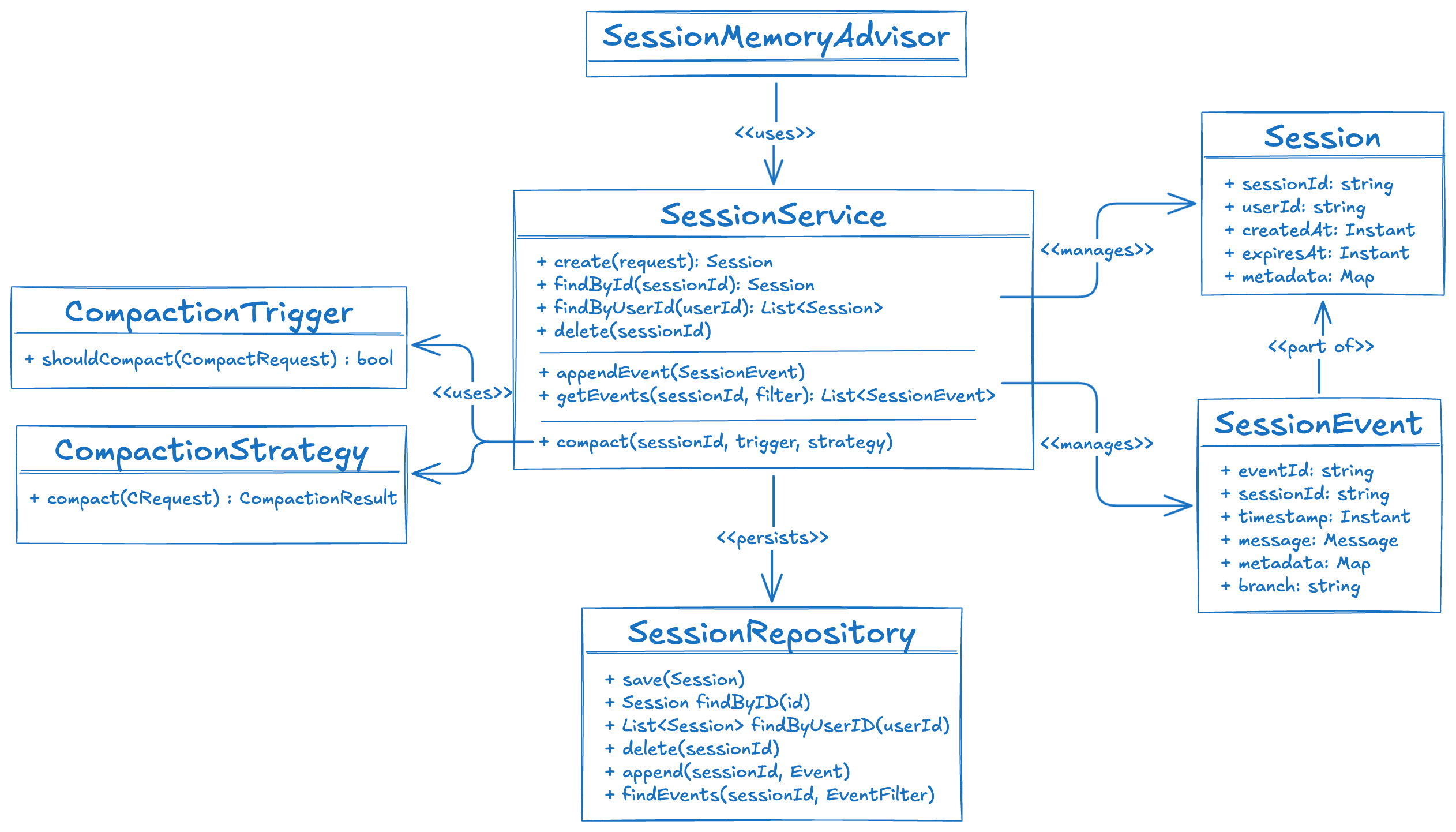
本文介绍 Spring AI 全新 Session API,采用事件溯源架构管理短期对话记忆,通过“轮次”原子化保障工具调用完整性,并提供可组合的上下文压缩触发器与策略,解决传统 ChatMemory 粗暴截断导致的上下文断裂问题,为多智能体协作提供结构化记忆底座。
入选理由:采用事件溯源日志替代扁平消息列表,以“轮次”为原子单位管理上下文,彻底避免工具调用序列被截断导致的模型幻觉。
Next.js 团队分享了将 AI Agent 视为一等公民的架构演进历程。通过废弃内置浏览器 Agent,转向基于 MCP 协议暴露框架内部状态,并引入结构化日志、agents.md 和 Next.js Skills,从根本上解决了 Agent 调试盲区与上下文缺失问题,为 AI 原生开发框架设计提供了新范式。
入选理由:AI Agent 调试需突破浏览器盲区,Next.js 通过 MCP 协议将运行时错误、路由与组件状态结构化暴露给外部 Agent。
Next.js 16.2 正式发布稳定的 Adapter API,通过定义类型化、版本化的构建输出契约,联合 OpenNext 及主流云厂商解决多实例部署下的缓存同步与流式渲染难题,并开源 Vercel 官方适配器以统一跨平台部署标准。
入选理由:Next.js 16.2 推出稳定版 Adapter API,提供类型化构建输出契约,消除跨平台部署的配置黑盒。
KernelEvolve将底层算子优化转化为LLM驱动的自动化搜索问题,通过闭环评测反馈,数小时内完成专家数周的手动调优。 系统支持NVIDIA/AMD/MTIA/CPU等异构硬件,自动生成Triton/CUDA等高性能Kernel,大幅提升模型吞吐。 Agentic编码方案打破人工调优瓶颈,为应对AI模型与硬件快速迭代的大规模基础设施优化提供可复用工程范式。
入选理由:KernelEvolve将底层算子优化转化为LLM驱动的自动化搜索问题,通过闭环评测反馈,数小时内完成专家数周的手动调优。
针对大型复杂代码库,采用多智能体预计算引擎提取隐性知识,比直接让AI扫描代码更高效准确。 AI上下文文件应遵循“指南针而非百科全书”原则,控制篇幅并聚焦关键路径、隐式规则与交叉引用。 构建自维护的知识层与自然语言路由机制,可显著降低AI工具调用开销,并实现与底层大模型的解耦。
入选理由:针对大型复杂代码库,采用多智能体预计算引擎提取隐性知识,比直接让AI扫描代码更高效准确。
Cloudflare在11个月内构建了基于自身平台的内部AI工程栈,覆盖93%研发人员,月处理4795万AI请求,显著提升代码合并效率。
入选理由:内部AI工具栈完全运行于Cloudflare对外产品上,实现自用即公测的开发闭环。
BestBlogs 正式发布 OpenAPI、CLI 和 Skills,以 Agent Native 理念重构阅读产品,使其成为可组合、可解释、可嵌入工作流的原语化能力节点。
入选理由:Agent Native 要求产品从界面中心转向工作流节点,支持人与智能体调用和组合。
Jim Fan团队开源CaP-X,推出具身智能体框架,支持多机器人平台,包含感知、控制、仿真训练及真实部署能力。
入选理由:CaP-X提供统一API支持机器人臂与人形机器人,实现零样本任务执行
OpenAI工程师提出“框架工程”理念:代码已成免费资源,人类应专注设定规范与约束,由AI智能体执行开发。
入选理由:代码实现成本趋近于零,稀缺资源是人类注意力和模型上下文窗口
Mem0 推出新记忆算法,在 LoCoMo 等基准上以不到 7,000 tokens/query 实现媲美竞品的准确率,显著降低推理成本。
入选理由:新算法通过单次 LLM 调用实现仅 ADD 的记忆提取,保留完整状态变迁历史
论文揭示模型蒸馏中存在隐式信息传递:即使训练数据不含敏感语义,同源初始化的学生模型仍会继承教师的行为偏好。
入选理由:同源初始化的模型可通过数据中的数字分布隐式传递行为特征
美团发布 LongCat-AudioDiT,通过波形潜空间端到端生成与两项推理优化,在零样本语音克隆中实现 SOTA 音色相似度。
入选理由:抛弃梅尔谱中间表示,直接在波形潜空间建模可减少信息损失
文章揭示RLHF训练中FP32与BF16精度差异引发的‘幻影裁剪’问题,导致PPO算法意外失效。
入选理由:FP32训练与BF16推理间的精度差产生结构化偏差β,非随机噪声
文章指出大模型深度扩展受限于层间通信瓶颈,提出用深度注意力替代残差连接,并通过Flash Depth Attention实现高效检索式信息流动。
入选理由:当前大模型深度扩展存在信息稀释问题,残差连接导致深层难以有效利用浅层信息。
Kimi团队提出PrFaaS架构,通过混合注意力模型与跨数据中心调度,实现KV Cache高效传输,显著提升长上下文推理吞吐与延迟表现。
入选理由:混合注意力架构大幅降低KV Cache带宽需求,使以太网可替代RDMA
ZJU-REAL团队开源ClawGUI框架,打通GUI智能体训练、评测与真机部署全流程,2B小模型在MobileWorld上SR达17.1,显著超越基线。
入选理由:ClawGUI实现训练-评测-部署闭环,解决GUI智能体研发割裂问题
Anthropic 在 Claude Opus 4.7 系统提示中新增儿童安全标签、工具搜索机制,并优化交互逻辑以减少冗长和侵扰性行为。
入选理由:新增 <critical_child_safety_instructions> 标签,强化儿童安全策略
文章深入剖析 AbortController 的信号-控制器分离架构、事件驱动机制及跨平台实现差异,揭示其协作式取消的设计哲学。
入选理由:AbortController 采用信号与控制器分离模式,确保职责单一和状态不可变
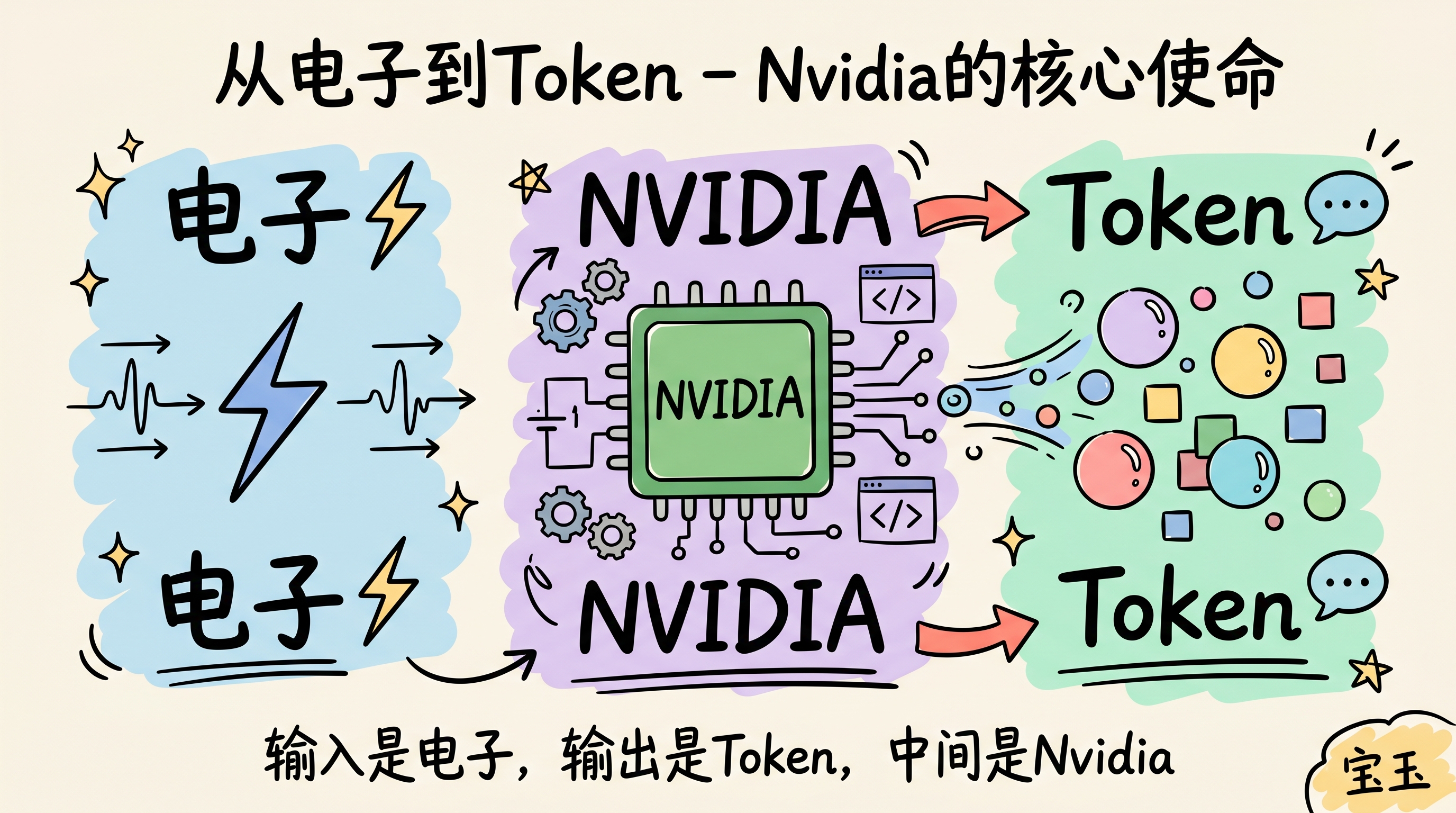
黄仁勋在深度访谈中阐释Nvidia以“电子转Token”为核心使命,强调CUDA生态、供应链协同与能源制约才是AI竞争关键。
入选理由:Nvidia护城河在于庞大GPU装机量、跨云可移植性及深度优化服务,而非单纯技术锁定。
Anthropic 推出 Claude Design,AI 主导生成可交互、可运行代码的高保真原型,颠覆传统设计工具协作模式。
入选理由:Claude Design 输出可运行 React 代码而非静态稿,支持真实交互与自动纠错
AWS 推出基于 Amazon Nova 多模态嵌入的视频语义搜索方案,可联合处理音视频、文本等多源信号,提升检索准确性与效率。
入选理由:传统视频搜索依赖文本转录,易丢失时空和音频信息
NVIDIA 利用合成数据训练出高性能多语言 OCR 模型 Nemotron OCR v2,在六种语言上显著降低错误率并实现每秒 34.7 页的推理速度。
入选理由:合成数据可兼顾标注精度与规模,有效解决多语言 OCR 训练数据稀缺问题
将Prompt视为产品设计,结合私有知识与行为数据,构建AI时代笔记工具的差异化护城河。
入选理由:AI拉平功能赛道,私有知识与行为数据成新壁垒
前Meta AI研究总监田渊栋深入剖析大模型效率瓶颈、创新路径与AI洪水下的人类定位,强调自进化、持续学习和科研品位的重要性。
入选理由:大模型已陷入资源内卷,扼杀多元创新,需转向效率与持续学习
Mario Zechner 批判当前 AI 编程工具过度复杂,主张回归极简设计,仅用读、写、编辑和 Bash 四工具构建高效智能体 Pi。
入选理由:主流 AI 编程工具因功能堆砌变得不可预测,陷入“宇宙飞船”陷阱
ElevenLabs CEO 揭示语音大模型如何通过神经网络实现情感与韵律的“涌现”,并分享其自服务驱动的高速增长与AI原生组织模式。
入选理由:语音模型近年才实现高拟真度,情感与口音通过大规模训练自然涌现
黄仁勋详解英伟达如何通过“电子到Token”转化构建护城河,并就对华芯片管制、能源瓶颈与GPU架构优势展开深度辩论。
入选理由:英伟达核心价值在于将电子高效转化为高价值AI Token,依赖软硬协同与供应链控制
Cloudflare 推出 Unweight,一种无损压缩技术,在 H100 GPU 上将 LLM 模型体积减少 15–22%,不牺牲推理质量且无需专用硬件。
入选理由:Unweight 实现 LLM 权重无损压缩,节省约 3GB VRAM,提升 GPU 利用率。
Cloudflare 推出共享字典压缩技术,利用浏览器缓存作为字典实现增量传输,显著减少重复部署带来的冗余带宽消耗。
入选理由:共享字典将用户已缓存的旧资源用作压缩字典,仅传输变更部分
Lakehouse多引擎环境下,SQL标识符解析规则不一致导致表和列不可见或查询失败,需通过统一命名规范和数据契约解决。
入选理由:Apache Iceberg等开放表格式未解决SQL方言差异,标识符解析仍依赖各引擎规则。
Medallia工程师分享在支持IE10等旧浏览器约束下,通过AST迁移、Preact替换和差异化加载等手段优化超大规模CX平台前端性能的实战经验。
入选理由:使用AST驱动的codemod实现React 15到现代版本的大规模安全迁移
提出Ecom-RLVE框架,将强化学习与可验证奖励机制引入电商对话代理,支持多轮、工具增强的购物任务。
入选理由:电商对话代理需从流畅性转向任务完成能力,传统微调难以覆盖复杂约束组合
Coding正推动AI从聊天机器人迈向能自主执行任务的Agent,成为AGI第二幕核心驱动力,并重塑硅谷大模型竞争格局。
入选理由:Coding是AGI发展的关键加速器,领先模型通过代码能力放大顶尖人才生产力10-50倍
Meta发布TRIBE v2,一个能高精度预测人脑对视听语言刺激反应的基础模型,支持零样本泛化并开源模型与代码。
入选理由:TRIBE v2基于700+志愿者fMRI数据训练,分辨率比同类模型高70倍
Meta发布SAM 3.1,通过对象多路复用和全局推理实现更快、更高效的实时视频检测与跟踪。
入选理由:SAM 3.1支持单次前向传播同时跟踪最多16个对象,视频处理速度翻倍。
AI体验设计正从提示工程转向约束优先架构,以解决大模型幻觉与可信度问题。
入选理由:提示仅能引导风格,无法保证事实准确性或防止幻觉。
Physical Intelligence发布π0.7模型,首次在机器人领域实现组合泛化,通才性能超越专才,标志VLA迎来GPT-3时刻。
入选理由:π0.7通过多层prompt机制有效利用多样化数据,无需清洗即可提升性能
MiniMax M2.7 实现模型自主迭代,Cursor 通过持续预训练提升编程能力,Cloudflare 将大模型推理嵌入边缘基础设施。
入选理由:M2.7 能自主优化评测系统与工作流,在100轮迭代中提升性能30%
文章探讨智能体工程化趋势,强调通过约束工程、结构化记忆和多智能体协作实现AI可靠编程。
入选理由:智能体工程化核心在于构建Harness约束体系,而非仅依赖模型能力
Anthropic 提出 Managed Agents 架构,通过 session、harness、sandbox 三层解耦,实现可恢复、可扩展、可治理的生产级智能体系统。
入选理由:harness 随模型进化易过时,需设计寿命更长的稳定接口
GitBook 在 Vercel 上托管 3 万文档站点,通过细粒度缓存与按标签失效机制,实现合并后 300ms 内全球内容更新。
入选理由:采用 Next.js 和 Vercel 的 use cache 指令实现函数级缓存,避免整页缓存浪费
文章深入讲解数据库索引原理,结合 PostgreSQL 示例演示如何创建、优化和避免误用索引以提升查询性能。
入选理由:索引通过独立数据结构加速查询,避免全表扫描,显著提升大数据量下的检索效率。
文章系统解析现代稀疏神经检索模型(如SPLADE++),对比关键词与稠密检索优劣,并展示其在Qdrant中的实践应用。
入选理由:稀疏神经检索结合BM25的可解释性与语义理解能力,优于传统关键词匹配
Cloudflare 推出 Artifacts:面向 AI Agent 的 Git 兼容版本化存储系统,支持按需创建仓库、导入现有 Git 项目并提供 REST/Workers API。
入选理由:Artifacts 是为 AI Agent 设计的分布式版本化文件系统,兼容 Git 协议。
Vercel 推出 Workflows,通过将编排逻辑内嵌于应用代码,实现无需独立 orchestrator 的持久化执行模型。
入选理由:Workflows 消除传统长流程所需的独立编排服务,状态与逻辑统一在应用代码中
Google MaxText 新增单机 TPU 上的监督微调(SFT)和强化学习(RL)支持,集成 Tunix 和 vLLM,简化 LLM 后训练流程。
入选理由:MaxText 现支持在单机 TPU(如 v5p-8)上运行 SFT 和 RL,降低后训练门槛。
OpenAI 发布 Codex 重大更新,支持跨应用操作、图像生成、记忆功能与自动化工作流,覆盖软件开发生命周期。
入选理由:Codex 现可操作系统应用、浏览器和终端,实现跨工具自动化开发任务。
本文详细指导如何基于 RustFS、Iceberg 和 Nessie 等开源组件构建可扩展的批处理数据湖,强调避免厂商锁定并支持未来扩展。
入选理由:使用 Docker 搭建包含对象存储、表格式和目录服务的单节点开源数据湖